Введение в реляционные базы данных
Структуры данных
Предположим, что мы решили основывать эту информационную систему на файловой системе и пользоваться одним файлом СЛУЖАЩИЕ, расширив базовые возможности файловой системы за счет специальной библиотеки функций. Поскольку минимальной информационной единицей в нашем случае является служащий, в этом файле должна содержаться одна запись для каждого служащего. Чтобы можно было удовлетворить указанные выше требования, запись о служащем должна иметь следующие поля:
- полное имя служащего (СЛУ_ИМЯ);
- номер его удостоверения (СЛУ_НОМЕР);
- данные о соответствии сотрудника занимаемой должности (СЛУ_СТАТ; для простоты «да» или «нет»);
- размер зарплаты (СЛУ_ЗАРП);
- номер отдела (СЛУ_ОТД_НОМЕР).
Поскольку мы решили ограничиться одним файлом СЛУЖАЩИЕ, та же запись должна содержать имя руководителя отдела (СЛУ_ОТД_РУК). (Иначе было бы невозможно, например, получить имя руководителя отдела с известным номером.)
Чтобы информационная система могла эффективно выполнять свои базовые функции, необходимо обеспечить многоключевой доступ к файлу СЛУЖАЩИЕ по уникальным ключам (ключ называется уникальным, если его значения гарантированно различны во всех записях файла) СЛУ_ИМЯ и СЛУ_НОМЕР. Очевидно, что в противном случае для выполнения наиболее часто используемых операций получения данных о конкретном служащем понадобится последовательный просмотр в среднем половины записей файла. Кроме того, должна обеспечиваться возможность эффективного выбора всех записей с общим значением СЛУ_ОТД_НОМЕР, т. е. доступ по неуникальному ключу. Если не поддерживать специальный механизм доступа, то для получения данных об отделе в целом в общем случае потребуется полный просмотр файла. Требуемая общая структура файла СЛУЖАЩИЕ показана на рис. 1.6. Но даже в этом случае, чтобы получить численность отдела или общий размер зарплаты, система должна будет выбрать все записи о служащих указанного отдела и посчитать соответствующие общие значения.
Таким образом, мы видим, что при реализации даже такой простой информационной системы на базе файловой системы возникают следующие затруднения:
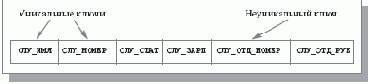
Рис. 1.6. Структура файла СЛУЖАЩИЕ на уровне приложения (случай одного файла)
- требуется создание достаточно сложной надстройки для многоключевого доступа к файлам;
- возникает существенная избыточность данных (для каждого служащего повторяется имя руководителя его отдела);
- требуется выполнение массовой выборки и вычислений для получения суммарной информации об отделах.
Кроме того, если в ходе эксплуатации системы потребуется, например, обеспечить операцию выдачи списков служащих, получающих указанную зарплату, то либо придется при выполнении каждой такой операции полностью просматривать файл, либо нужно будет реструктурировать файл СЛУЖАЩИЕ, объявляя ключевым и поле СЛУ_ЗАРП.
Для улучшения ситуации можно было бы поддерживать два многоключевых файла: СЛУЖАЩИЕ и ОТДЕЛЫ. Первый файл должен был бы содержать поля СЛУ_ИМЯ, СЛУ_НОМЕР, СЛУ_СТАТ, СЛУ_ЗАРП и СЛУ_ОТД_НОМЕР, а второй – ОТД_НОМЕР, ОТД_РУК (номер удостоверения служащего, являющегося руководителем отдела), ОТД_СОТР_ЗАРП (общий размер зарплаты сотрудников данного отдела) и ОТД_РАЗМЕР (общее число сотрудников в отделе). Структура этих файлов показана на рис. 1.7.
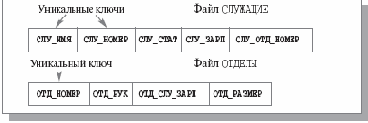
Рис. 1.7. Структура файла СЛУЖАЩИЕ и ОТДЕЛЫ на уровне приложения (случай двух файлов)
Введение этих двух файлов позволило бы преодолеть большинство неудобств, перечисленных в предыдущем абзаце. Каждый из файлов содержал бы только не дублируемую информацию, не возникала бы необходимость в динамических вычислениях суммарной информации по отделам. Но заметим, что при таком переходе наша информационная система должна обладать некоторыми новыми особенностями, сближающими ее с СУБД.